I am not too clear on how SIMD processing differs from superscalar execution, since both of them work with a single instruction stream. For SIMD, are we distributing different chunks of the data to different ALUs while in superscalar execution the parallelizable instructions are assigned to different ALUs?
kayvonf
This is great question. Can someone take a shot at an answer?
truenorthwest
The key difference is that superscalar execution will simultaneously process different independent instructions (such as A+B and C*D), whereas SIMD will execute the same instruction onto a vector/array of data (A[0]+B[0] and A[1]+B[1]). The SIMD calculations also need to be independent of each other.
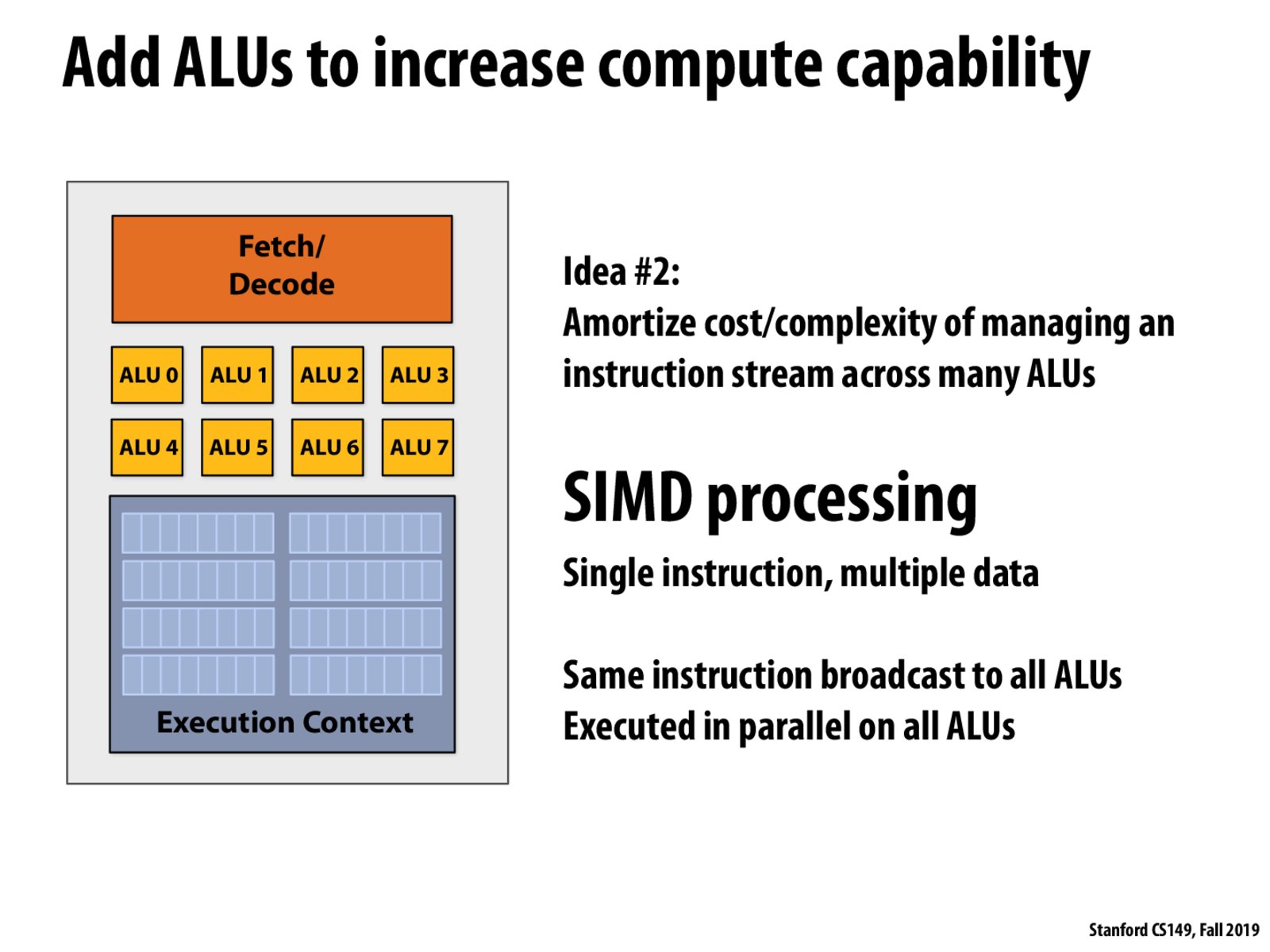
Architecturally, both methods may required multiple ALUs, but superscalar will also require additional fetch/decode blocks (slide 13). For implementation, the SIMD parallelism tends to be determined at compile time for modern CPUs and in the hardware for modern GPUs, while modern superscalar tends to be implemented in the hardware for runtime determination.
At a higher level, my understanding is that superscalar could theoretically do everything that SIMD can (by just using the same instruction on different data) and also execute different instructions, but at a greater hardware cost. Though perhaps someone else can elaborate on the pro/cons more.
I am not too clear on how SIMD processing differs from superscalar execution, since both of them work with a single instruction stream. For SIMD, are we distributing different chunks of the data to different ALUs while in superscalar execution the parallelizable instructions are assigned to different ALUs?
This is great question. Can someone take a shot at an answer?
The key difference is that superscalar execution will simultaneously process different independent instructions (such as A+B and C*D), whereas SIMD will execute the same instruction onto a vector/array of data (A[0]+B[0] and A[1]+B[1]). The SIMD calculations also need to be independent of each other.
Architecturally, both methods may required multiple ALUs, but superscalar will also require additional fetch/decode blocks (slide 13). For implementation, the SIMD parallelism tends to be determined at compile time for modern CPUs and in the hardware for modern GPUs, while modern superscalar tends to be implemented in the hardware for runtime determination.
At a higher level, my understanding is that superscalar could theoretically do everything that SIMD can (by just using the same instruction on different data) and also execute different instructions, but at a greater hardware cost. Though perhaps someone else can elaborate on the pro/cons more.